Never thought this would happen, but I was stumped by my own application for a good 24 hours before realizing what was happening. I’m getting too old for this ****
A user wrote in asking why SQL Image Viewer could identify XML content in his SQL Server table, but he could not use his database’s XML functions to query the XML data.
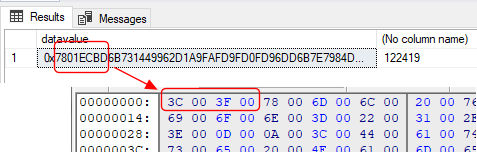
No problem, or so I thought. Using a subset of the database he sent, I could see the first few bytes of the XML content and also query the size in SSMS:
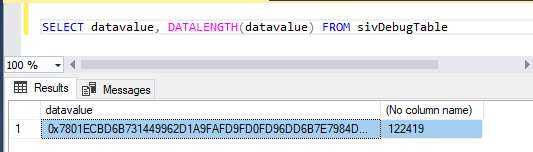
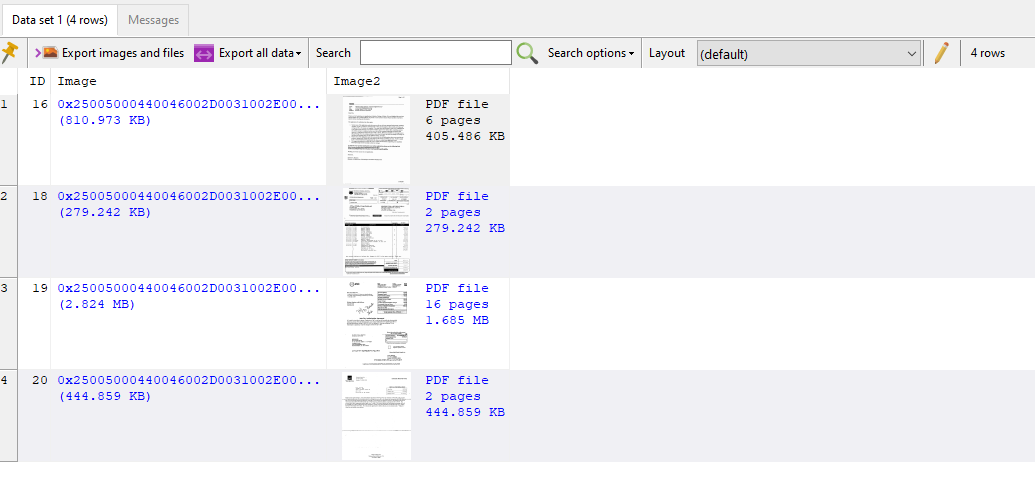
Ok, so that’s about 119 Kb of data. In SQL Image Viewer, the following is returned:
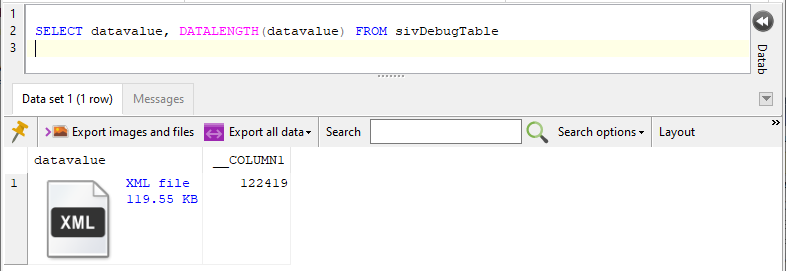
So far so good, SQL Image Viewer identified the XML content. Now what happens when I try to use the XML function in SSMS:
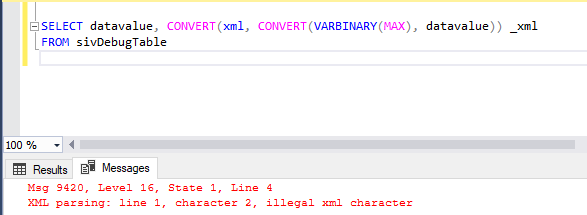
SQL Server raised an error: XML parsing: line 1, character 2, illegal xml character
Ok, so what’s wrong with character 2? Back in SQL Image Viewer, I opened the hex viewer, and the XML header looked fine:
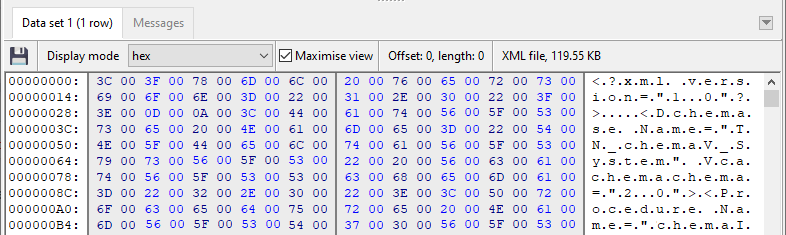
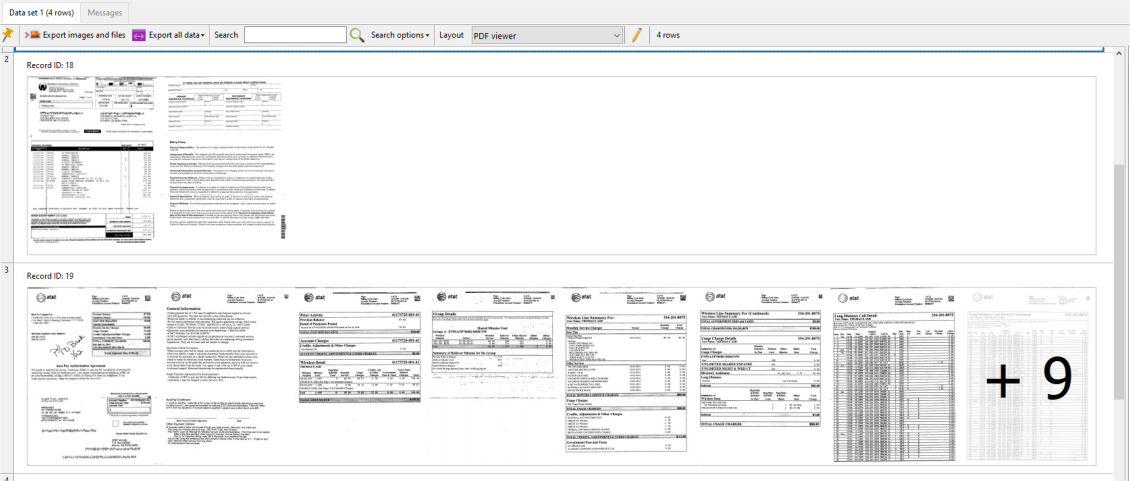
Ok then, I decided to export the XML file to disk, and could open it in my browser. Then it stuck me that the file was over 2 MB in size, but the blob size was only 119 Kb.

What was going on here? In the hex viewer I scrolled to the end of the XML content, and it too was indicating the content was about 2.6 MB in size.

Why was SSMS and SQL Image Viewer reporting the blob size as 119 Kb, but when viewed in the hex viewer or exported, the content was closer to 2.6 MB in size?
This being a SQL Server database, my first thought was that row or column compression was in place. However, the compression/decompression would have been done transparently and wouldn’t be showing up this way. I checked anyway, and sure enough, no row/column compression was active.
Feeling rather lost, I explained the situation to the user hoping they might shed some light on what was going on. Later, in the shower, while clearing my head (literally and figuratively), it stuck me: zlib streams.
Basically, if the blob content is a zlib compressed stream, SQL Image Viewer automatically decompresses the stream, identifies the content type, and lets you work with the decompressed data. That was exactly what was happening here – the zlib compressed stream of 119 Kb was being uncompressed to 2.6 MB, identified as an XML file, and subsequent viewing and exporting allowed me to work with the uncompressed data. I had totally forgotten about this feature!
This also explained why the XML functions could not work directly on the blob content – it was a zlib stream and not a XML text file.
Next time, I should compare the first few bytes as displayed in SSMS against the values displayed in SQL Image Viewer. It would then have been immediately clear that we were working with a compressed stream.
And that is how my own application fooled me (or my memory is just getting poorer).