Task – you need to extract text from your PDF files
Options – you can find hundreds of online sites that can do that for you.
Concern – your files are confidential, and you’re not sure if those sites are making copies of your files for ‘other’ purposes.
Practicality – you want to extract text from hundreds or thousands of files, and processing each file online is going to be veeeeeery boring.
Try Easy PDF Explorer, a Windows application that helps you extract text your PDF files directly on your computer.
User interface
Easy PDF Explorer uses the familiar Windows Explorer interface, so you can easily navigate your folders and select your files.
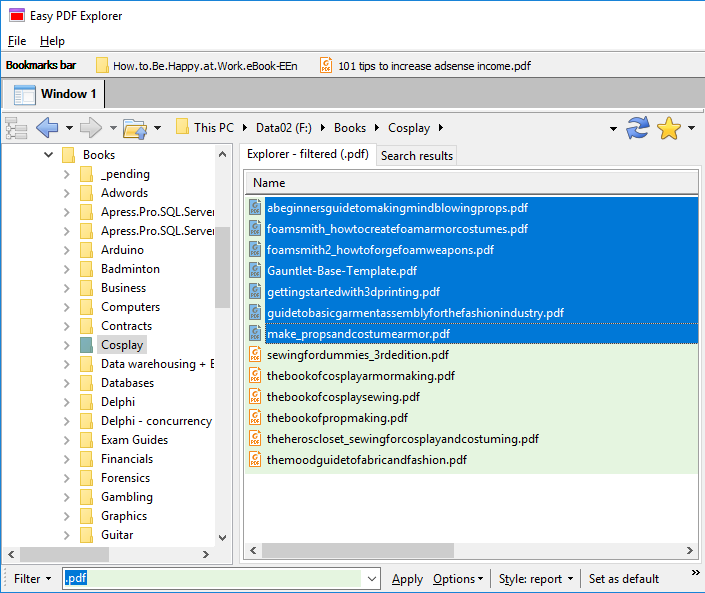
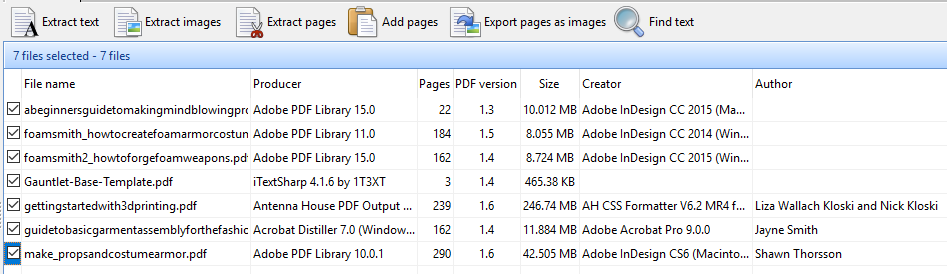
Select 1 or more PDF files, and Easy PDF Explorer will display the details of each file. This is one benefit of Easy PDF Explorer – it allows you to work with batches of PDF files easily.
Extract text from PDF
When you want to start extracting text from your PDF files, click on the Extract text button:
This brings up the Extract Text window.
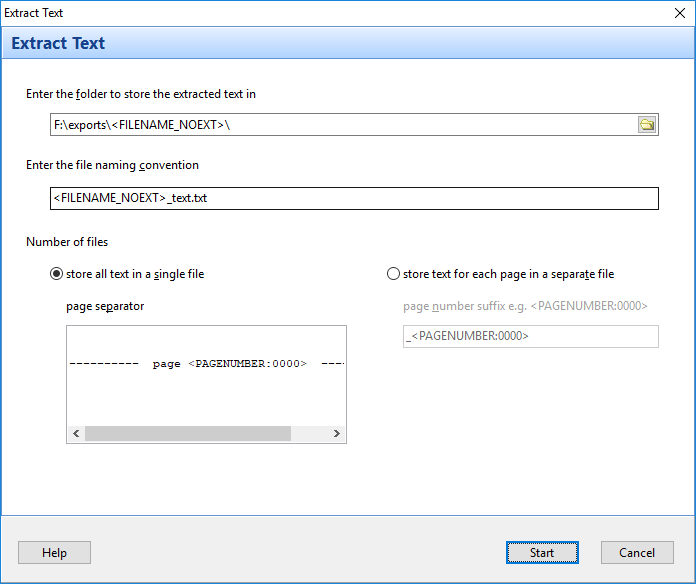
You need to enter the folder you want to store the extracted text in. You also need to provide the naming convention for the extracted pages, and if you want the text from each page to be saved to a different file.
In this example, we will be storing the images from each file in its own folder.

We use the <FILENAME_NOEXT> tag, so for a file named Accounting.pdf, all text from that file will be stored in the f:\exports\Accounting\ folder.
We will use the default naming convention of <FILENAME_NOEXT>_text.txt.

This uses the PDF file name and append the _text value to the file. So in our example, our extracted text will be stored in a file named Accounting_text.txt.
Next, we need to choose if we want to store all the text from our PDF file into a single file, or separate them by pages into individual files.
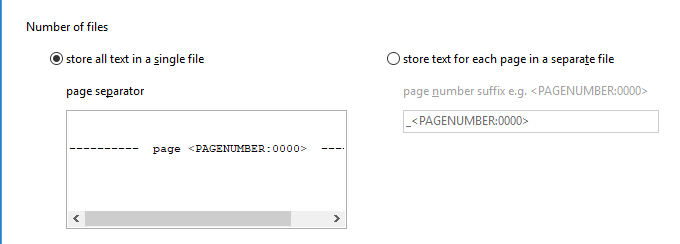
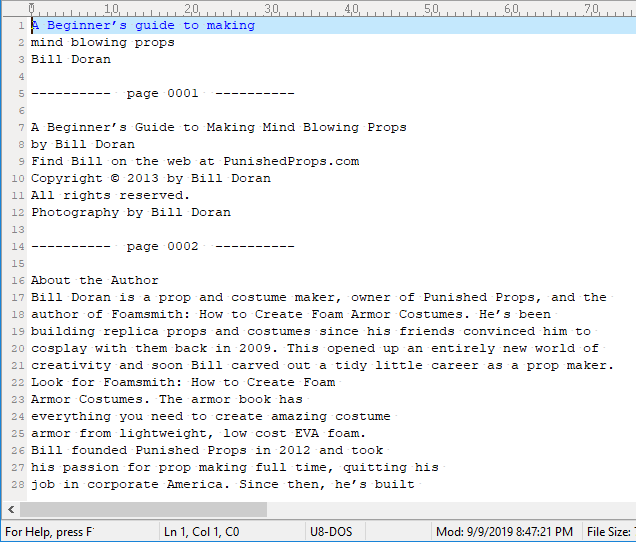
If we choose a single file as per the above screenshot, we can enter a page separator value. The default page separator will separate each page this way:
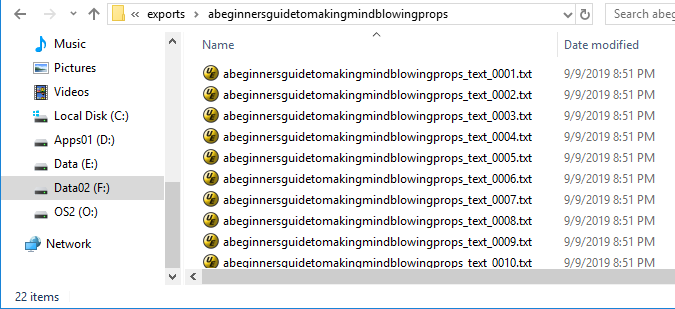
If you choose to store the text from each page in a separate file, then you need to enter a suffix for each of the files.

The default suffix of _<PAGENUMBER:0000> will create files this way:
And that’s all there is to it. Use Easy PDF Explorer to extract text from your hundreds or thousands of PDF files, on your computer, securely and fast.
Other Easy PDF Explorer features
In addition to extracting text from your PDF files, Easy PDF Explorer can also:
- extract images from your PDF files
- split your PDF files
- merge/combine PDF files
- export pages as JPEG, PNG, or bitmap images
- extract text and images from PDF to Word
- search for text across multiple PDF files
Download a 14-day trial now, and see how Easy PDF Explorer can help you work with your PDF files faster and safer.