OLE Object fields are commonly used by applications using Access as the back-end database to store files and common document formats. It is convenient because Windows handles how the files or documents are opened, modified, and saved via OLE servers. However, it is difficult to extract the data from those fields because of the additional OLE information embedded together with your data.
For example, let’s create a table in Access, and store a simple Excel workbook, first as an embedded object, and second as an embedded file. Our table structure is as follows:
We create the first record by directly embedding an Excel workbook.

For the second record, we simply attach an existing Excel workbook.
In Access, we can open both workbooks easily simply by double-clicking on them. This is the OLE servers at work.

Now if we take a look at the size of the 2 records using SQL Image Viewer, we can see that the size of the embedded workbook is larger than the attached file. The size of the attached file record is also larger than the original file size, because Access needs to add additional data to the file.
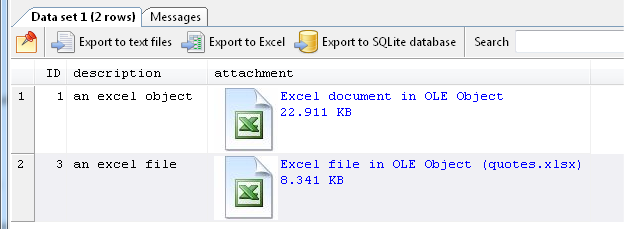
If you try to export the data as is, you will not be able to open the exported files, because the format itself is not Excel-compliant. Both records in the OLE Object fields have had additional OLE wrappers added to them.
The usual way to extract the content is to open each item individually in Excel, and save them to files. This is a tedious process if you have a lot of records you need to extract.
We have 2 products, SQL Image Viewer and Access OLE Export, that can remove the OLE wrappers for data stored in OLE Object fields, and export them to disk.
SQL Image Viewer is for technical users who are comfortable writing SQL queries to retrieve the required data.
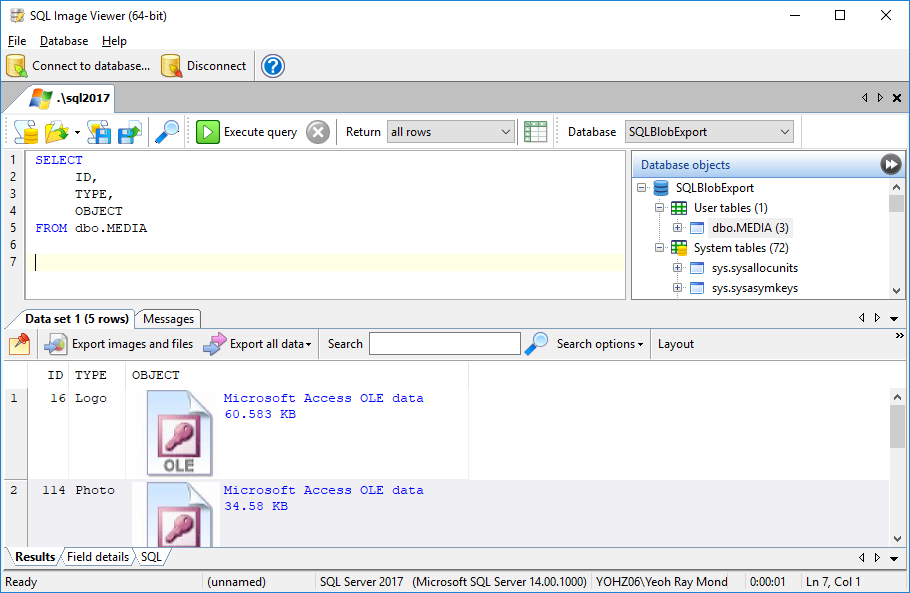
Access OLE Export is for less technically inclined users who just want to be able to select a table and export their data quickly.
Both products can identify embedded Office document content, images, PDF content, Open Document content, and other common binary types. Both products can also extract data from OLE Object fields used in other database engines like SQL Server, MySQL, Oracle, PostgreSQL, Firebird, SQLite, and ODBC data sources.
There may be situations where both products are unable to identify embedded content correctly. This may be because the registered OLE Server for that content type is not yet supported. For e.g. PDF files can have different OLE servers like Adobe Acrobat, Foxit PDF Reader. Nitro, etc. In these cases, send us (at support@yohz.com) a sample of the embedded data, and we will add support for that OLE server type.
Download a FREE 14-day trial of SQL Image Viewer or Access OLE Export now, and see how easy it is to export your ‘trapped’ OLE Object data.
If instead you need to insert or update OLE-Object data in your databases, have a look at Access OLE Import. Using Excel spreadsheets as the input data, you can easily add and update your embedded or linked OLE-Object data.
You can purchase our products on this page.
See also: