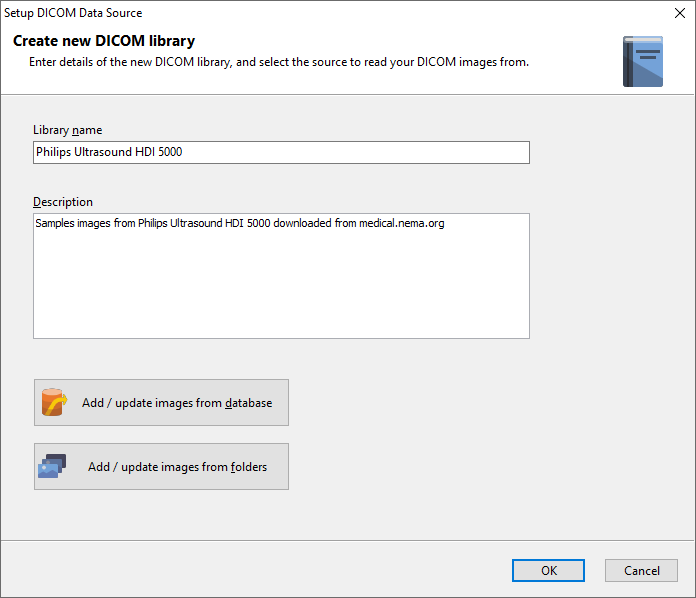
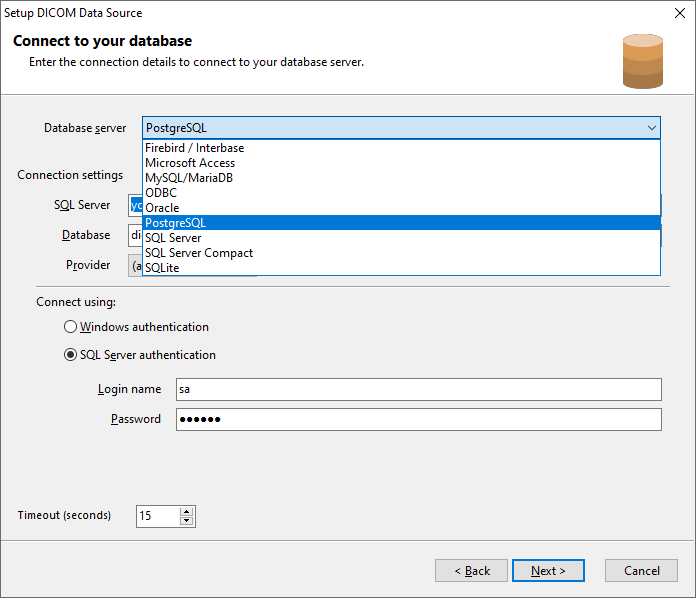
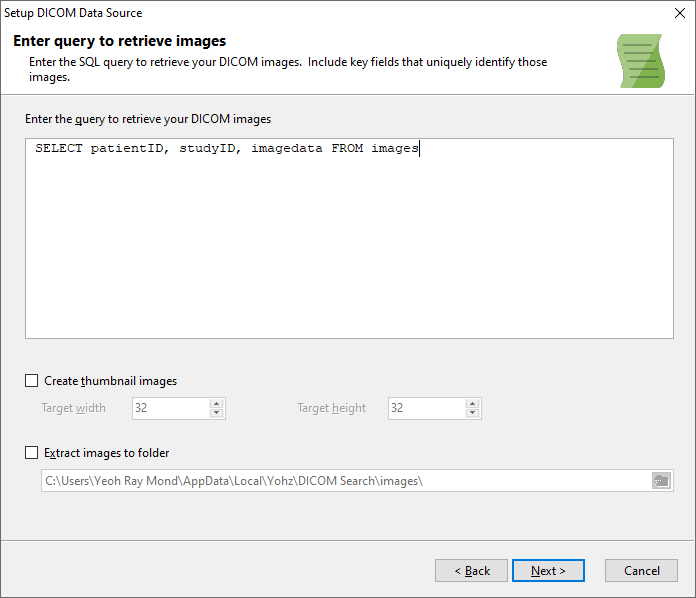
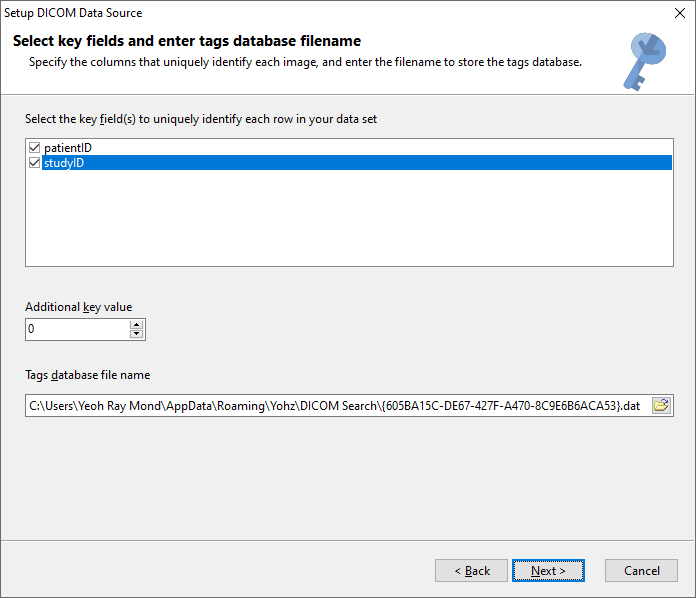
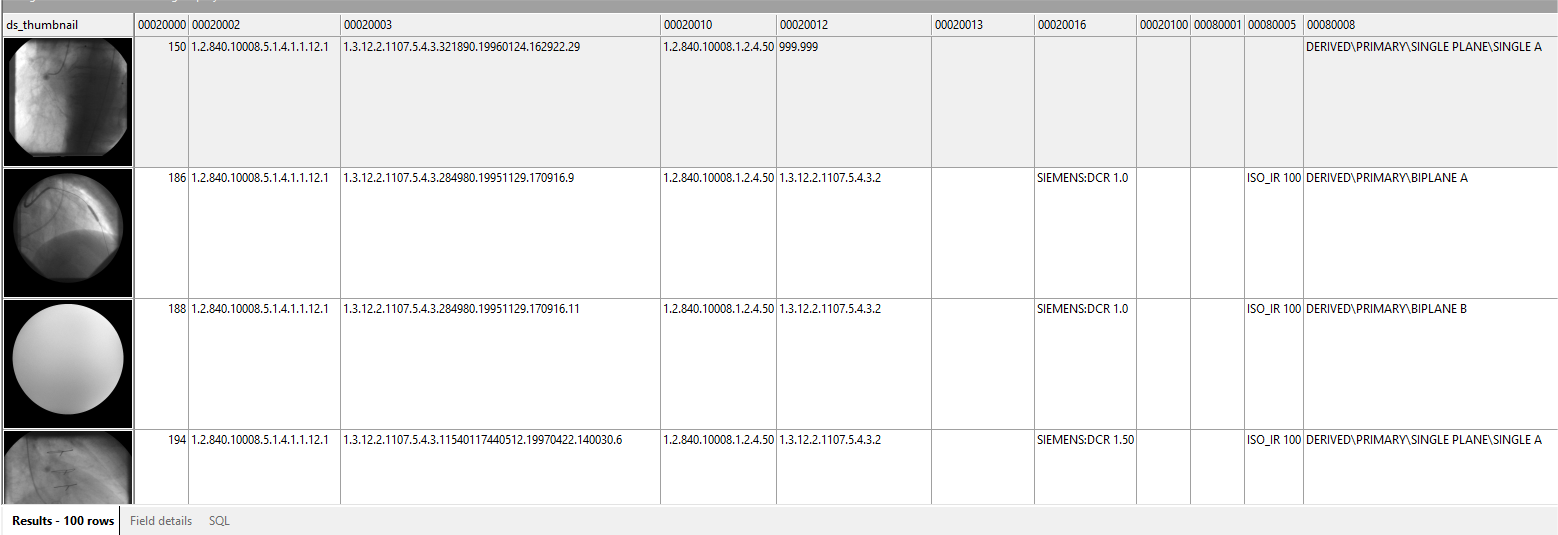
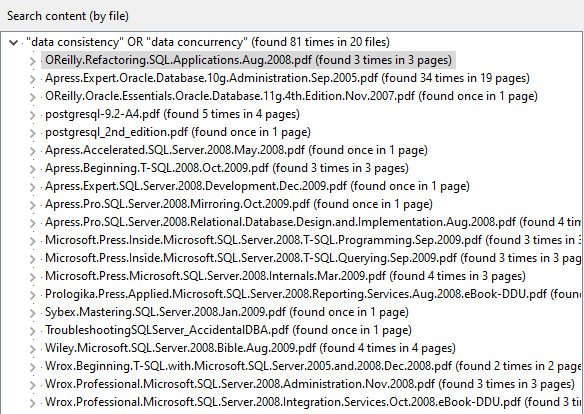
Once DICOM Search has indexed the DICOM tags in your images, you can run queries against the tags table. Selecting everything from the tags table, while possible, isn’t very useful and is very slow.
The reason is because there are over 2800 fields, and DICOM Search will struggle to maintain and display that many columns. Thus, it is recommended that you select only the fields you are interested in.
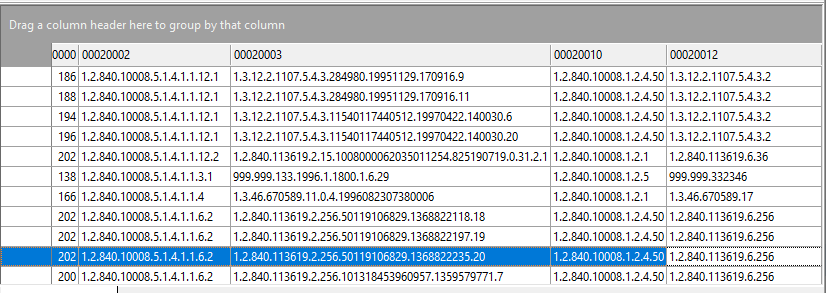
You can quickly see which fields are available in your database by pressing F2 when in the SQL editor to bring up the Tags and Fields window.
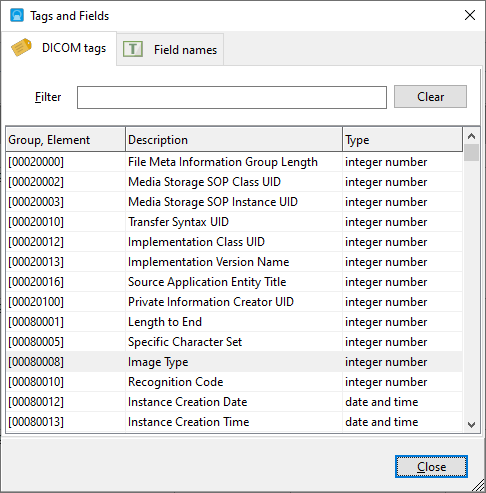
Clicking on any of the tag values will add that value to the SQL editor area, so you do not need to manually enter the tag name. In addition to the DICOM tags, there are also additional fields that DICOM Search populates in the tags table, as listed in the Field names tab.
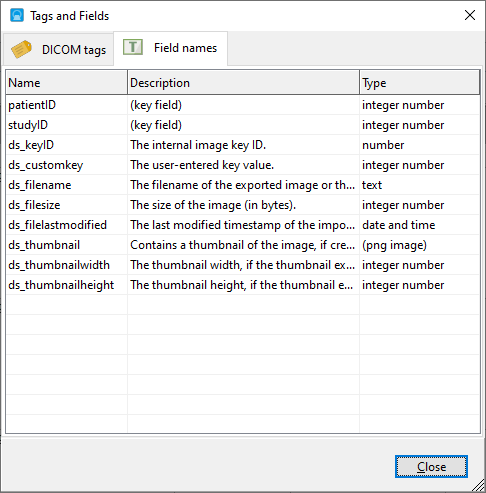
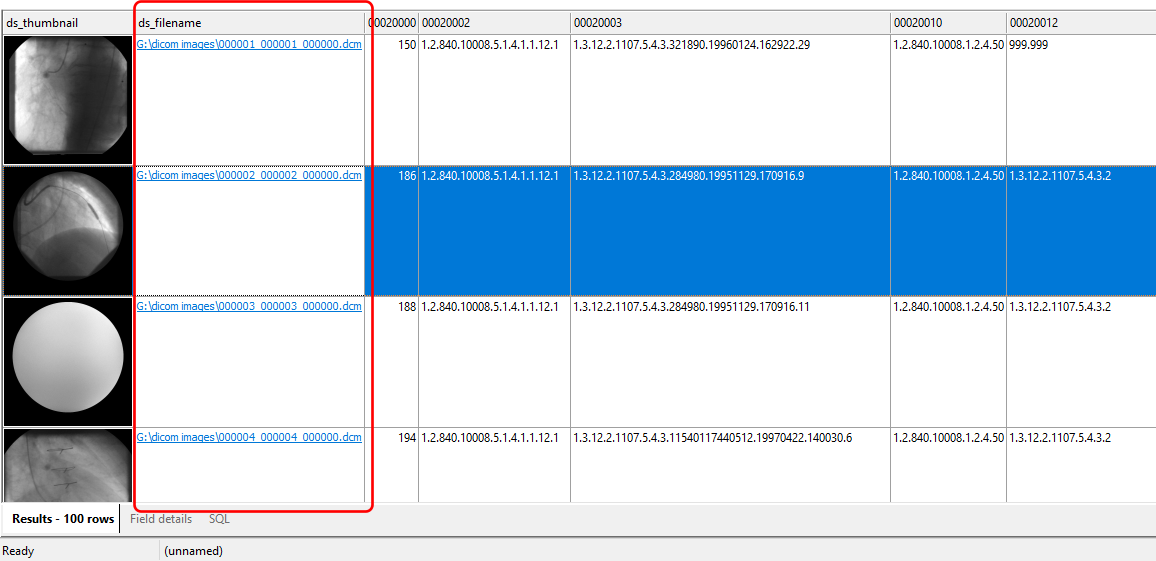
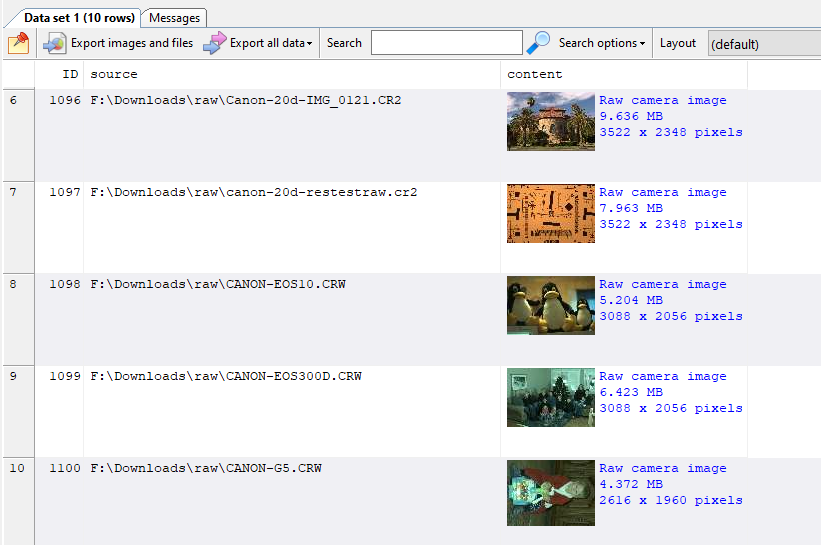
In addition to your key fields, the other fields are used by DICOM Search to maintain a record of the processed images. For the users, the useful fields are ds_thumbnail and ds_filename. ds_thumbnail stores a thumbnail of the image and ds_filename stores the location of the image file when exported from your database, or when processed from your folder.
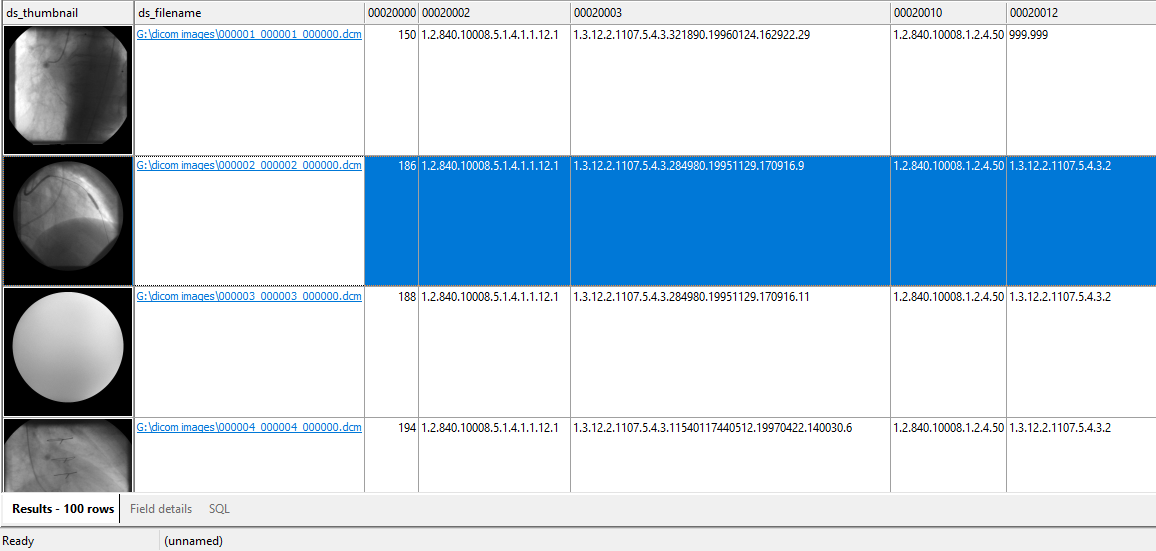
If the listed file name is present on your computer, you can open the image file in your DICOM viewer by double-clicking on the file name in DICOM Search.
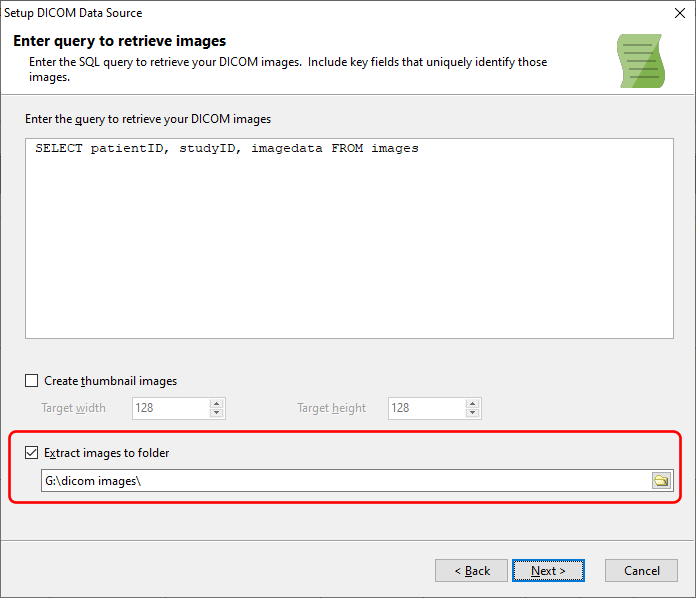
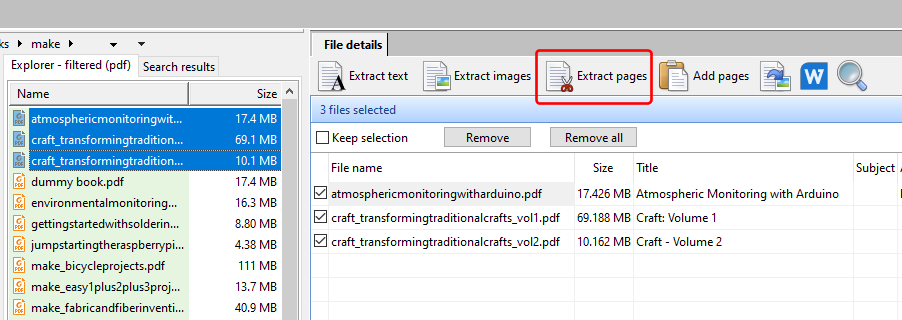
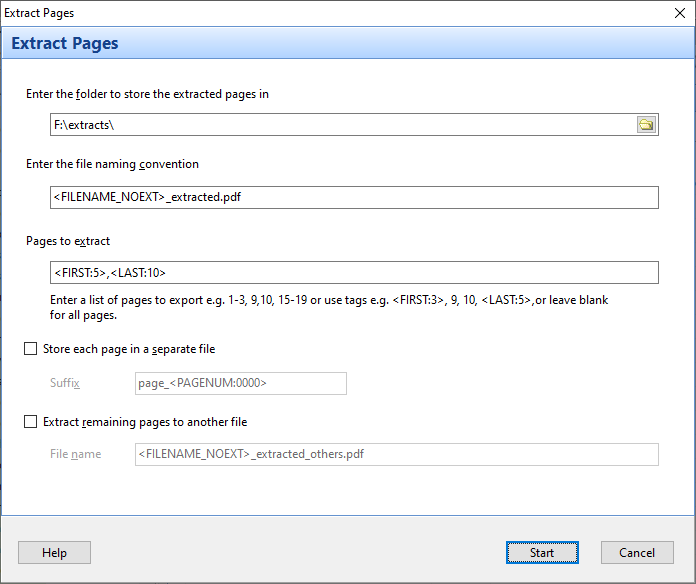
Please see this post on how to index and extract images from your database to your computer using DICOM Search, and also how to add thumbnails to the tags database.
SQL syntax
The tag values are stored in a SQLite database, so you will use the SQLite SQL syntax to query the database. In our example, our key fields are patientID and studyID, so we will always select those columns in case we want to query the source database. We also select the ds_thumbnail and ds_filename columns to view the image thumbnail, and also have a link to the actual image.
Here are some examples of the types of queries you can run:
- searching text values
E.g. the Patient Name (tag group and element 0010,0010):SELECT patientID, studyID, ds_thumbnail, ds_filename FROM tags WHERE [00100010] = ‘Rubo’ - searching for part of a text value
E.g. to return all images where the patient name starts with Rubo:SELECT patientID, studyID, ds_thumbnail, ds_filename FROM tags WHERE [00100010] LIKE ‘Rubo%’E.g. to return all images where the patient name contains the word Rubo:SELECT patientID, studyID, ds_thumbnail, ds_filename FROM tags WHERE [00100010] LIKE ‘%Rubo%’E.g. to retrieve all images there the patient name ends with Rubo:
SELECT patientID, studyID, ds_thumbnail, ds_filename FROM tags WHERE [00100010] LIKE ‘%Rubo’
- searching date values
E.g. the Study Date tag (tag group and element 0008,0020) for all studies made between Jan 1 1993 and Jan 1 1994:SELECT patientID, studyID, ds_thumbnail, ds_filename, [00080020] FROM tags WHERE [00080020] >= ‘1993-01-01’ AND [00080020] < ‘1994-01-01’Key point is you need to always enter the value you want to search for using yyyy-mm-dd format (year-month-date) - searching time values
E.g. the Study Time tag (tag group and element 0008,0030), for all studies made between 1 PM and 2 PM.SELECT patientID, studyID, ds_thumbnail, ds_filename, [00080030] FROM tags WHERE [00080030] >= ’13:00′ AND [00080030] < ’14:00′Key point is you need to always enter the value you want to search for using hh:mm:ss format (hour:minutes:seconds). - searching numbers
You can use all the usual equality and comparison symbols for numbers e.g. =, >, >=, <, <=E.g. the Intervention Drug Dose tag (tag group and element 0018,0028), where the value is greater than 25SELECT patientID, studyID, ds_thumbnail, ds_filename, [00180028] FROM tags WHERE [00180028] > 25
You can combine multiple conditions using the AND and OR operators e.g.
SELECT patientID, studyID, ds_thumbnail, ds_filename, [00080030] FROM tags WHERE ([00080020] >= ‘1993-01-01’ AND [00080020] < ‘1994-01-01’ AND [00080030] >= ’13:00′ AND [00080030] < ’14:00′) OR ([00100010] = ‘Rubo’)
To sort the results, use the ORDER BY option, and specify the field to sort by e.g. to sort the results by patient name (tag group and element
SELECT patientID, studyID, ds_thumbnail, ds_filename, [00080030] FROM tags WHERE ([00080020] >= ‘1993-01-01’ AND [00080020] < ‘1994-01-01’) ORDER BY [00100010]
To sort in descending order, add the DESC option after the field name e.g.
SELECT patientID, studyID, ds_thumbnail, ds_filename, [00080030] FROM tags WHERE ([00080020] >= ‘1993-01-01’ AND [00080020] < ‘1994-01-01’) ORDER BY [00100010] DESC
To limit the number of rows returned, use the LIMIT option. For e.g. to retrieve the first 30 rows where the Intervention Drug Dose value is greater than 25, sorted by that field in descending order
SELECT patientID, studyID, ds_thumbnail, ds_filename, [00180028] FROM tags WHERE [00180028] > 25 ORDER BY [00180028] DESC LIMIT 30
See also: