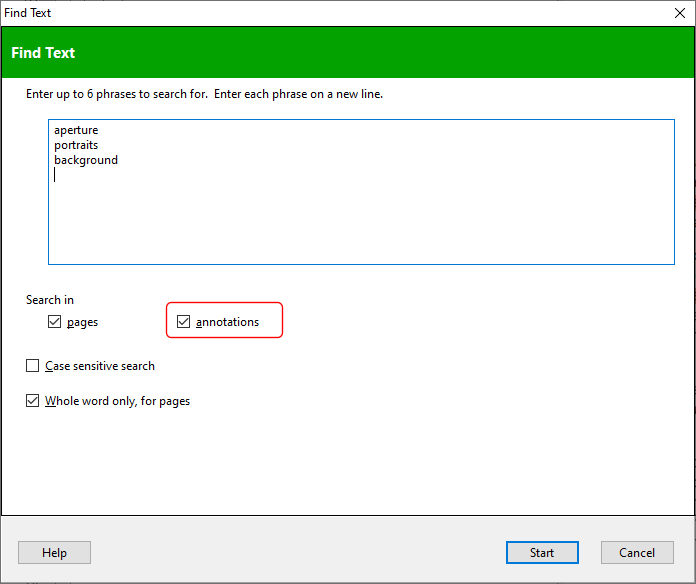
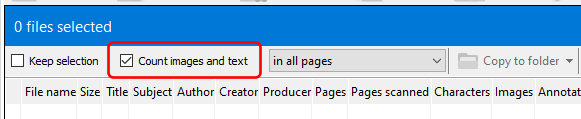
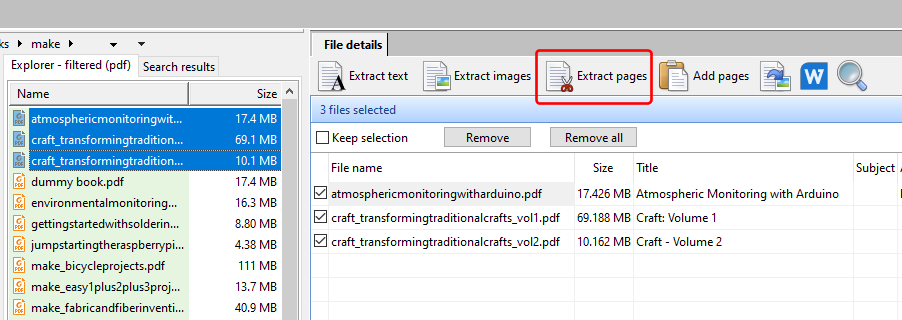
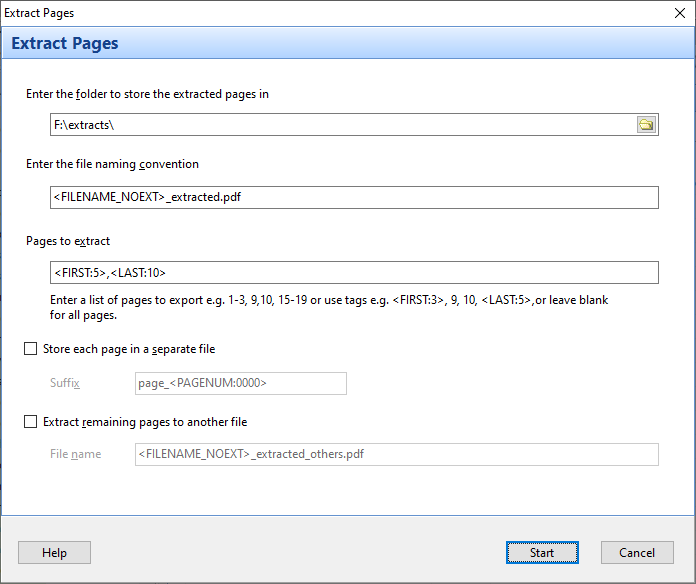
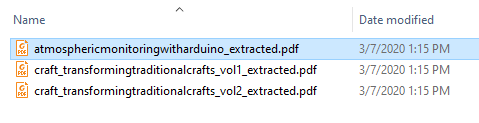
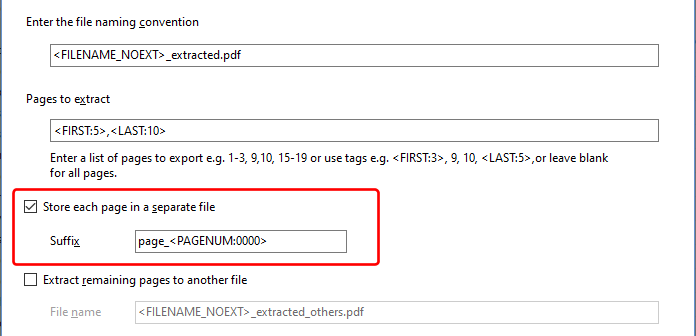
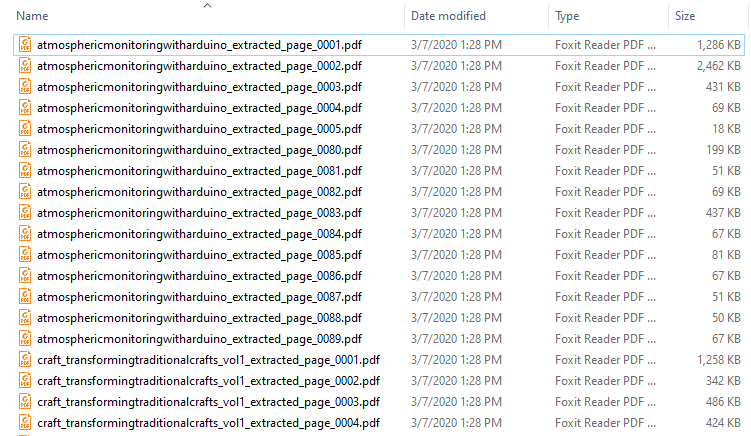
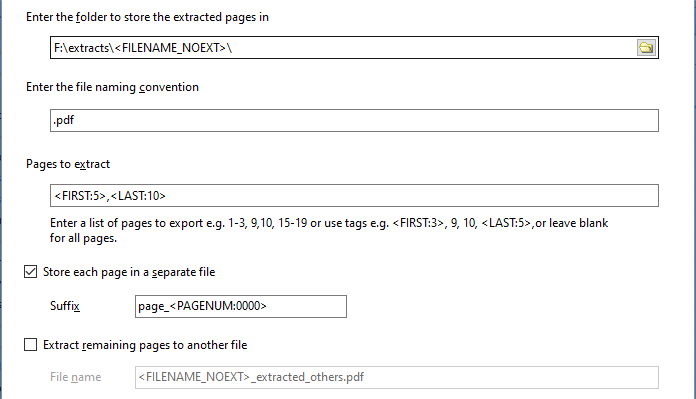
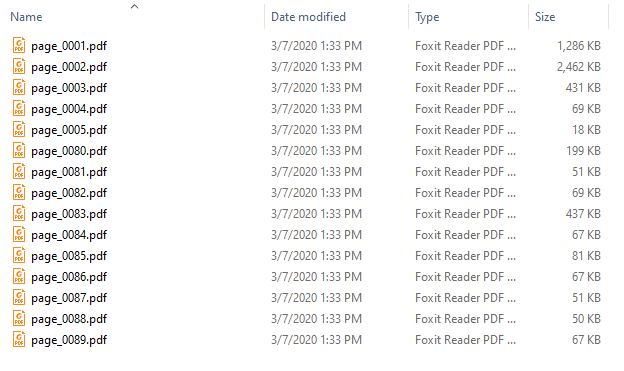
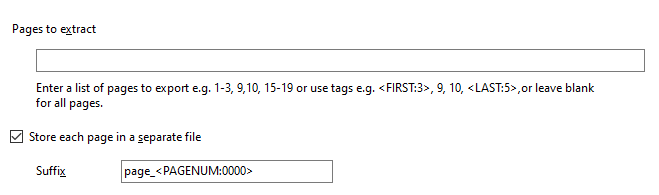
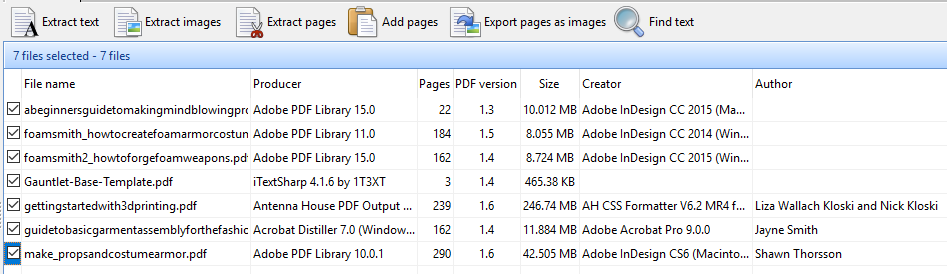
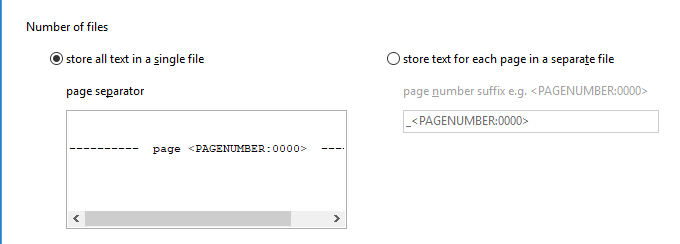
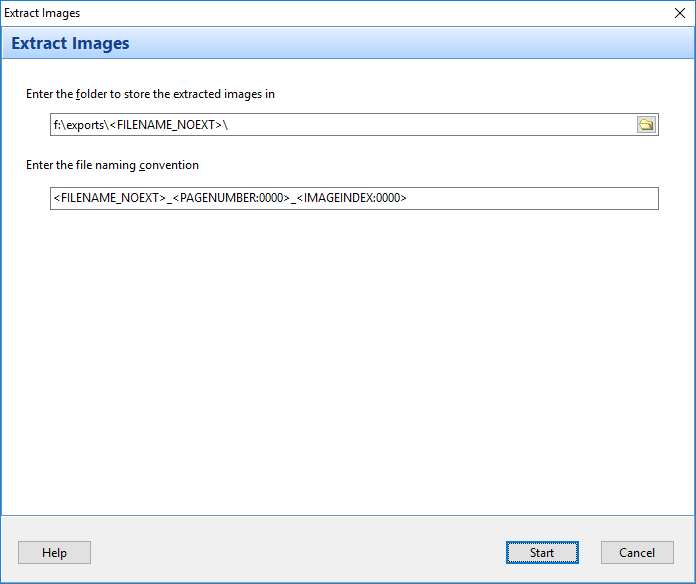
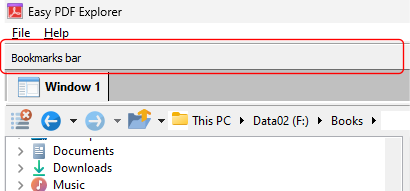
The Bookmarks bar in Easy PDF Explorer appears below the main menu in Easy PDF Explorer.
Using the Bookmarks bar
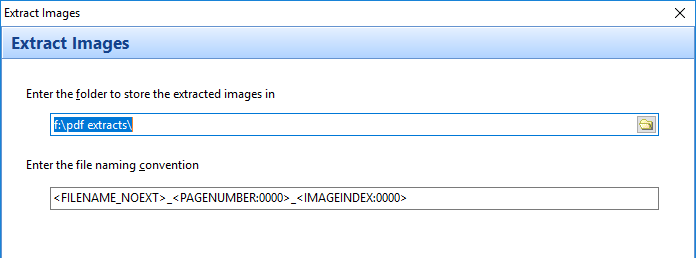
The bookmarks lets you quickly open a folder or file by clicking on the item on the Bookmarks bar. To place an item, drag and drop the folder or file from the Explorer window to the Bookmarks bar.
For example, this is the visual representation when you drag a folder over the Bookmarks bar.
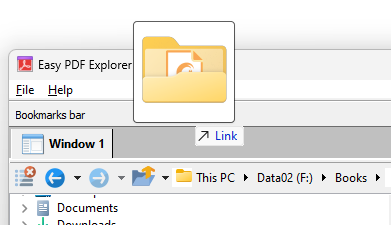
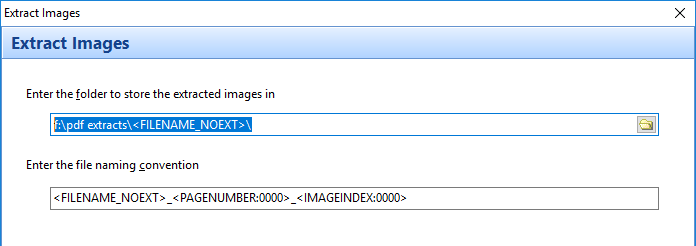
When you drop the item on the Bookmarks bar, a button is created to represent the folder.

When you now click on that button, the active Explorer window will open to that folder.
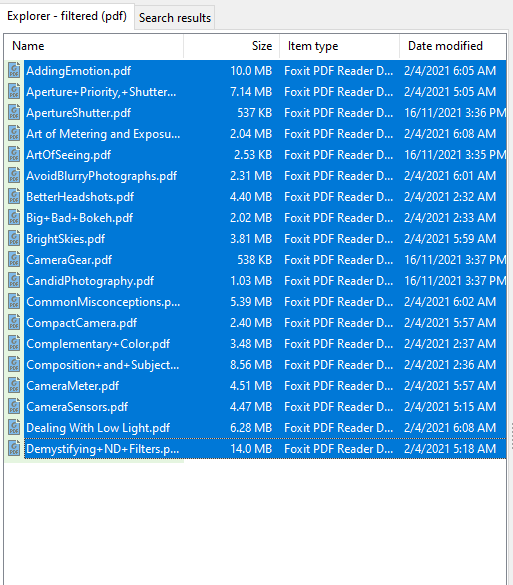
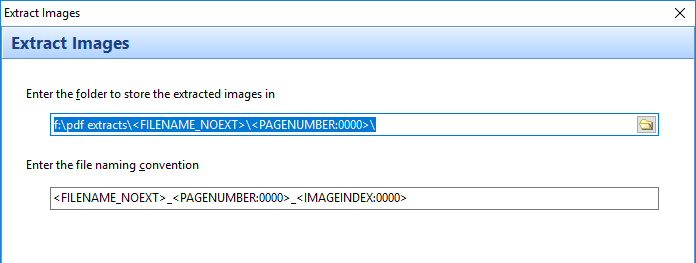
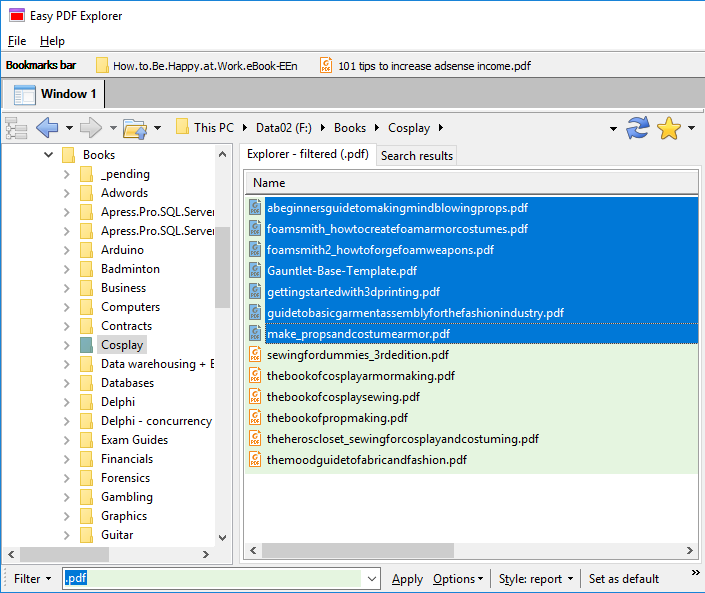
Similarly, when you drag a file item on to the Bookmarks bar, a button is created for that file. In the image below, we have 2 file items – a PDF file and an Excel workbook.
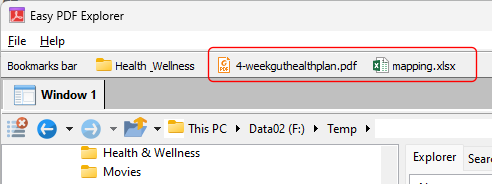
When you click on the file name on the Bookmarks bar, the active Explorer window will open to the folder containing that file, and highlight the file name.
Opening the context menu for items on the Bookmarks bar
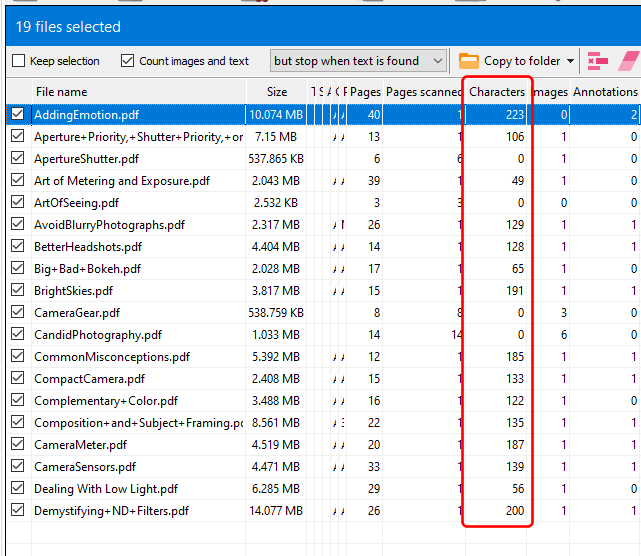
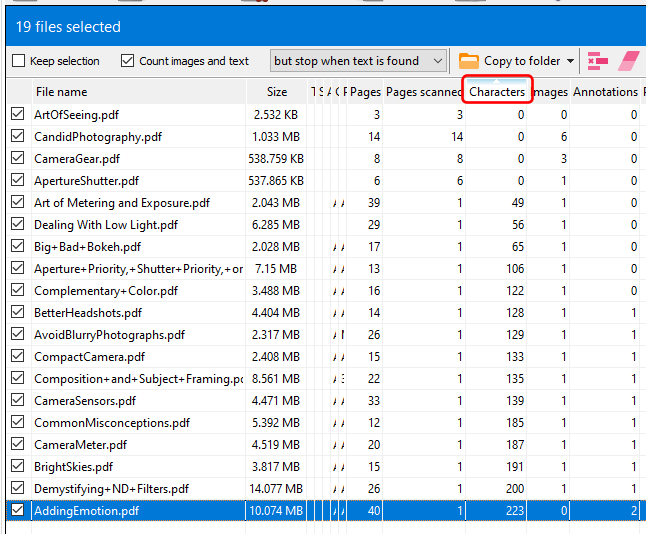
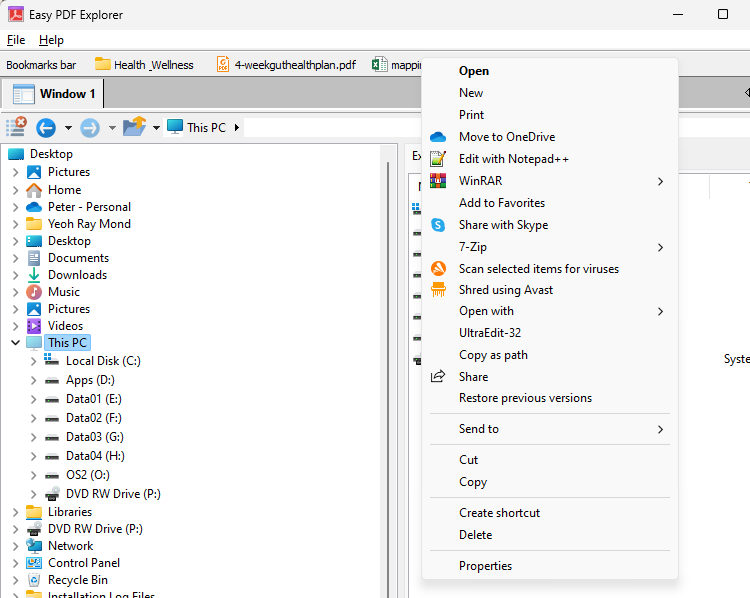
You can open the context menu associated with the folder or file item by right-double-clicking on the button in the Bookmarks bar. The image below shows the context menu when we click on our Excel file item.
Rearranging items on the Bookmarks bar
Right click on the folder or file item, then drag and drop the item on its new position.
Removing items from the Bookmarks bar
Right click on the folder or file item and drag it away from the Bookmarks bar.