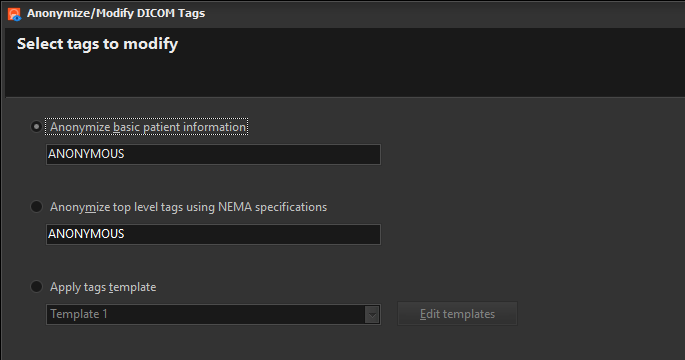
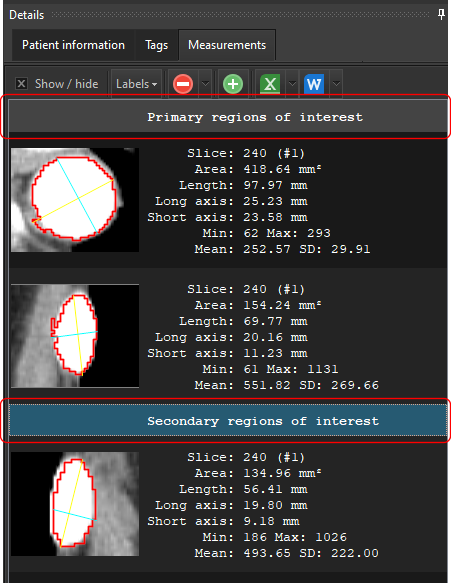
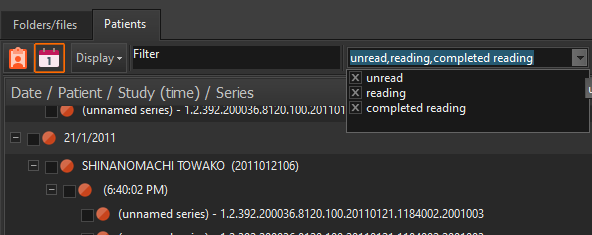
In Easy DICOM Viewer 5, you can now create contact sheets from images containing multiple slices/frames.
Say we have a series containing 94 slices.
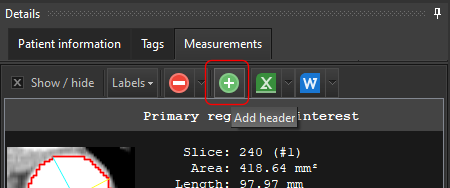
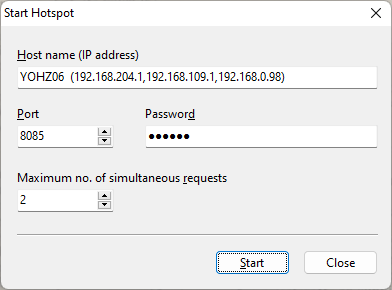
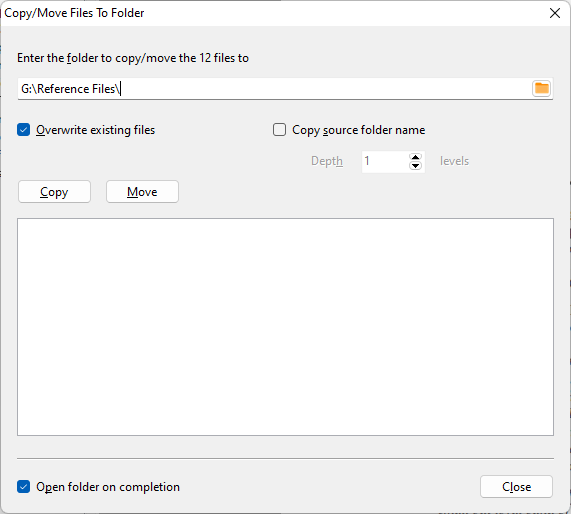
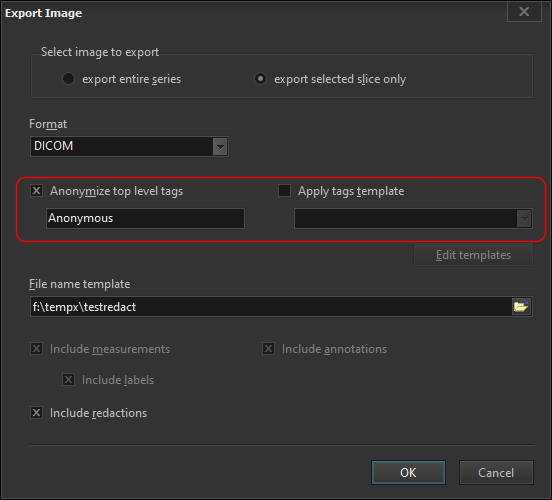
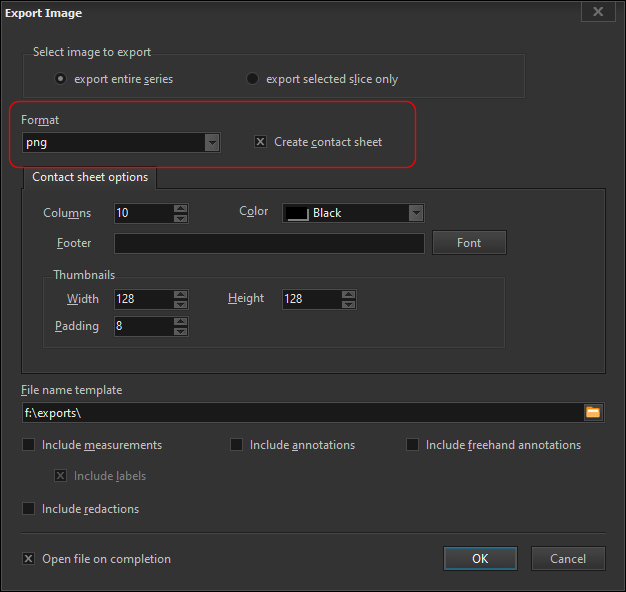
We want to export all 94 images into a single PNG file. When we choose the Export Image action, we select the Create contact sheet option.
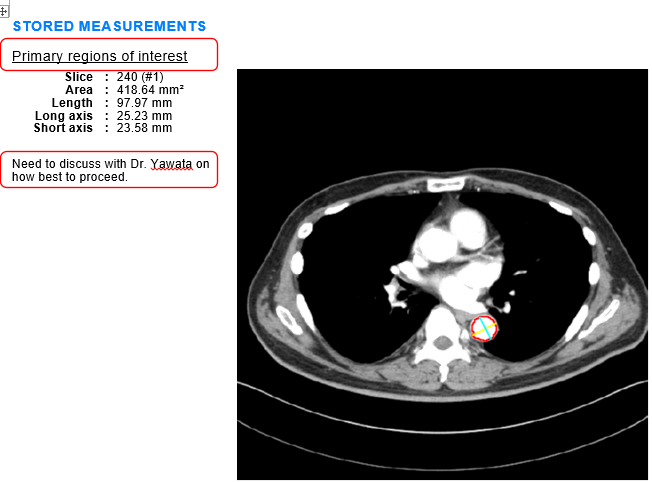
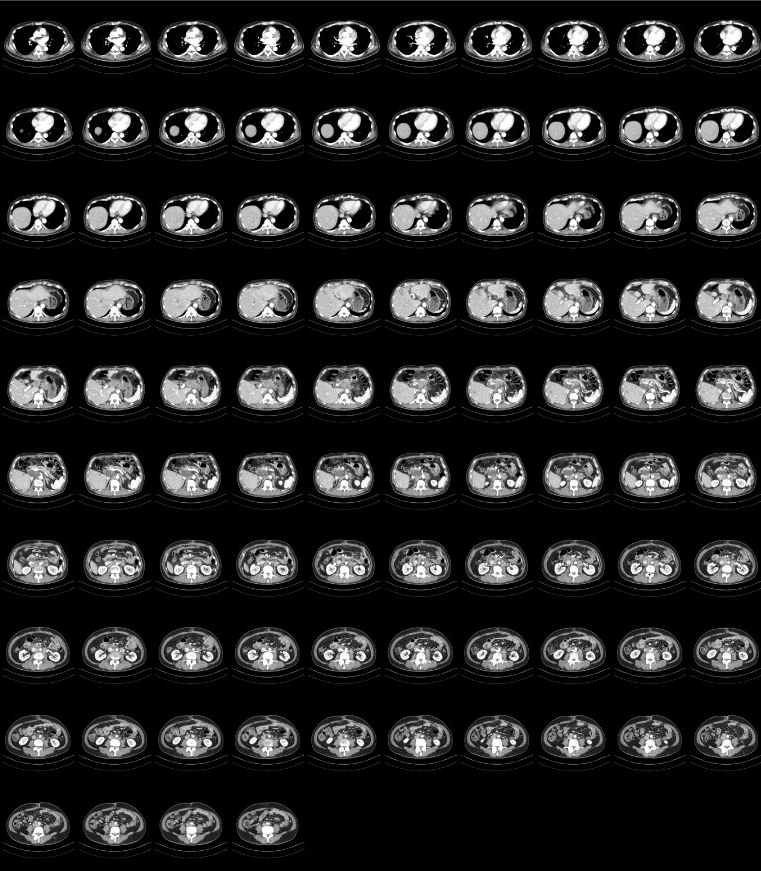
Once exported, our PNG file looks like this:
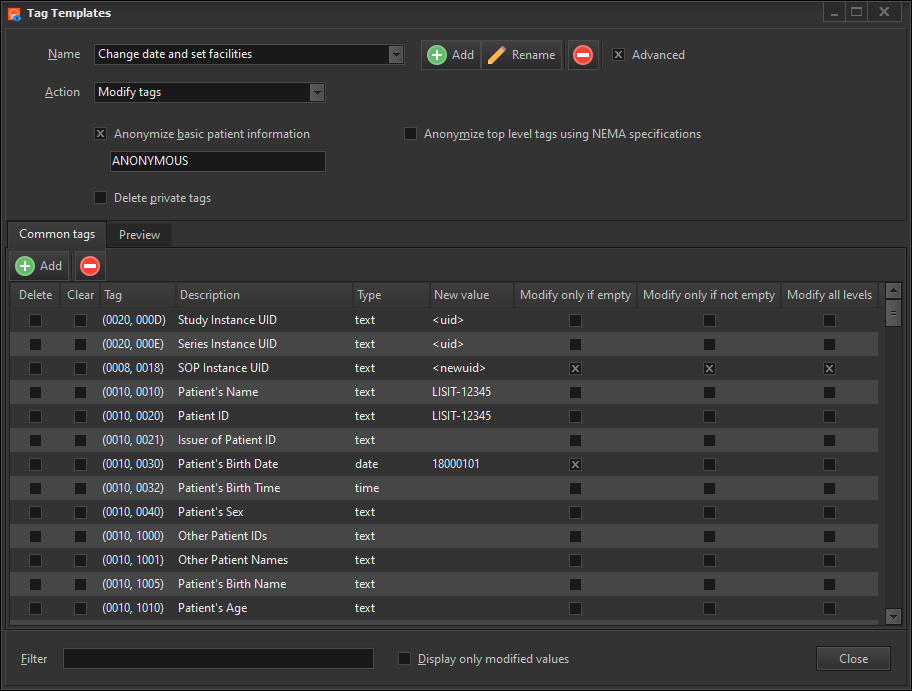
You have full control over how the images are rendered. You define how many columns to use, the size of each image, the background color, and the footer value.
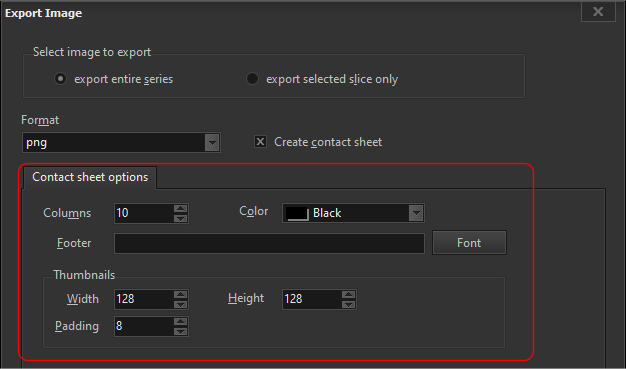
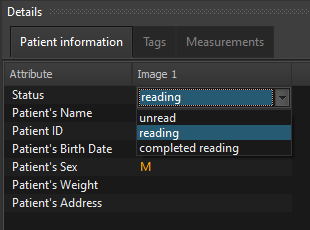
What exactly is the footer value? It’s whatever value you want displayed at the bottom of each image. It can be static text, which isn’t very useful, or it can be one or more DICOM tag values.
For e.g. let’s say we want to display the slice location at the bottom of each image. The tag we want is 0020, 1041. We simply enter this value as the footer value e.g.
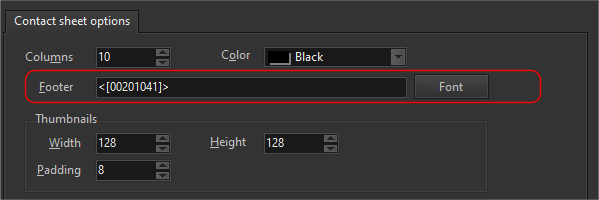
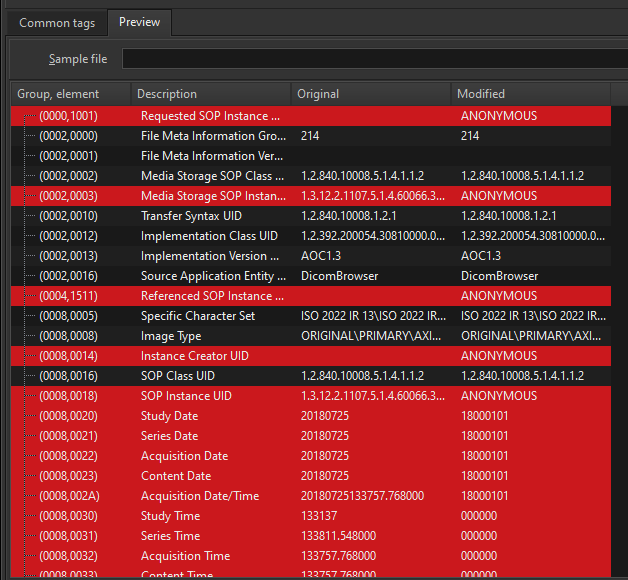
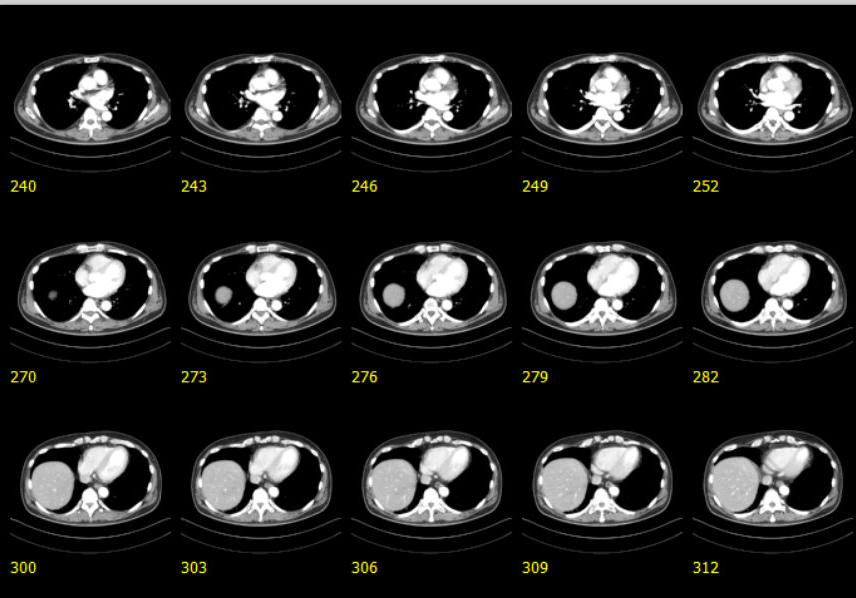
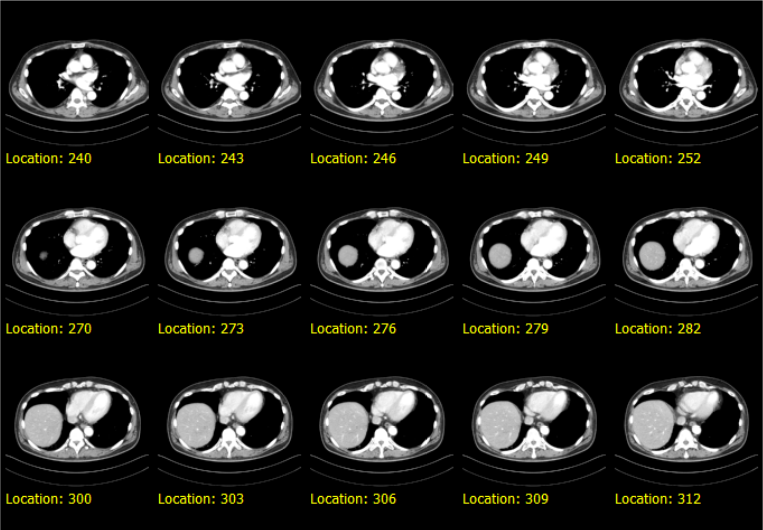
When we now export the PNG contact sheet, the slice location is displayed on the bottom of each thumbnail.
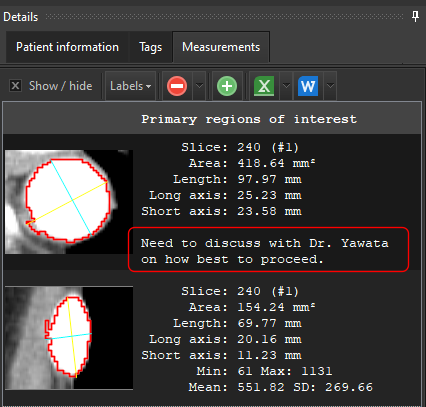
We could of course add some label to the value. Say we add the label Location: to the value e.g.
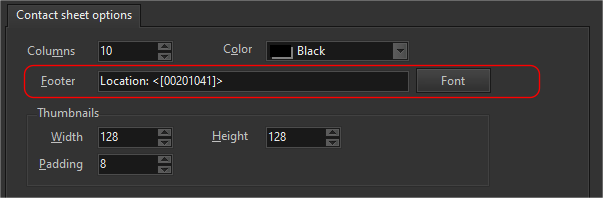
resulting in this:
Download a 14-day trial of Easy DICOM Viewer now, and see how you can easily identify which images require your attention.
Easy DICOM Viewer is a collaborative effort between LISIT, Co., Ltd. and Yohz Software. To learn more about Easy DICOM Viewer or download a trial, please use this link. If you are in Japan, please use this link instead.
See also: